Pengantar: Dalam posting bagian ini akan dibahas perancangan basis data
terdistribusi berikut masalah-masalah yang berkaitan dengannya.
Seperti halnya proses perancangan sistem lainnya, perancangan basis data terdistribusi juga memerlukan serangkaian proses analisis dan desain. Termasuk di dalam proses ini adalah analisis kebutuhan beserta proses-proses perancangan, yakni desain secara konseptual bersama dengan desain tampilan (view) informasi; desain distribusi yang melibatkan pengaturan pembagian data; kemudian desain fisik (lihat gambar).
bagan proses perancangan basis data terdistribusi
Fragmentasi
Dalam basis data terdistribusi, fragmentasi dilakukan pada relasi-relasi yang ada pada basis data. Fragmentasi membagi suatu relasi yang ada menjadi sejumlah fragmen atau pecahan relasi yang tetap mempertahankan keutuhan informasi semula. Kelebihan dari fragmentasi, yang menjadi alasan dilakukannya adalah dimungkinkannya pemrosesan data secara paralel dan penempatan tupel relasi, yang berisi sejumlah informasi, pada tempat yang tepat, yaitu yang paling membutuhkannya. Fragmentasi sendiri terbagi atas empat jenis, yaitu:
- primary horizontal: sebuah relasi R(A1, …, An) difragmentasi berdasarkan himpunan predikat-predikat relasi PR = {p1, …, pn}. Tiap-tiap predikat merupakan perbandingan yang digunakan dalam aljabar relasional, yang dapat melibatkan operator perbandingan =, ?, <, atau >.
- derived horizontal: pembuatan partisi suatu relasi R berdasarkan partisi yang dibuat pada relasi lain, misalkan S. Satu atau beberapa atribut di R mengacu kepada primary key pada S.
- vertical: fragmentasi ini dilakukan dengan memisah-misahkan atribut-atribut dari skema relasi R ke dalam skema-skema Ri. Setiap fragmen relasi harus memiliki primary key relasi asli.
- hybrid: fragmentasi yang mempunyai pola campuran dari ketiga relasi di atas
Ilustrasi Fragmentasi
Misalkan ada dua relasi sebagai berikut:
PEGAWAI(NoPeg, NamaPeg, Posisi, Gaji, NoDep)
DEPT(NoDep, NamaDep, Lokasi)
Contoh fragmentasi untuk tiga jenis fragmentasi yang telah disebutkan di atas adalah sebagai berikut:
- dalam fragmentasi primary horizontal, dimisalkan ada himpunan predikat yang diakses oleh aplikasi yang berbeda. Satu aplikasi memperoleh informasi pegawai dengan posisi DBAdmin, sementara aplikasi lainnya memperoleh informasi pegawai dengan gaji lebih besar dari Rp 15 juta. Predikat sederhana dapat dinyatakan dalam himpunan sbb: . Selanjutnya, predikat-predikat dapat dinyatakan ke dalam himpunan dari minterm, yaitu
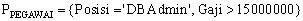 . Selanjutnya, predikat-predikat dapat dinyatakan ke dalam himpunan dari minterm, yaitu sebagai berikut
. Selanjutnya, predikat-predikat dapat dinyatakan ke dalam himpunan dari minterm, yaitu sebagai berikut - m1 = Posisi = ‘DBAdmin’ ^ Gaji > 15000000
- m2 = Posisi ? ‘DBAdmin’ ^ Gaji > 15000000
- m3 = Posisi = ‘DBAdmin’ ^ Gaji = 15000000
- m4 = Posisi ? ‘DBAdmin’ ^ Gaji = 15000000
- dalam fragmentasi derived horizontal, misalkan DEPT dipartisi berdasarkan predikat Lokasi = ‘Bandung’, sehingga ada dua partisi
DEPT1 = sLokasi = ‘Bandung’(DEPT)
DEPT2 = sLokasi ? ‘Bandung’(DEPT)
sementara, itu PEGAWAI dipartisi berdasarkan partisi DEPT sebagai berikut:
PEGAWAIi PEGAWAI left outer join DEPTi
- dalam fragmentasi vertical, relasi PEGAWAI(NoPeg, NamaPeg, Posisi, Gaji, NoDep) difragmentasi ke dalam fragmen relasi PEGAWAI1(NoPeg, NamaPeg, Gaji) dan PEGAWAI2(NoPeg, Posisi, NoDep).
Ketepatan Fragmentasi
Fragmentasi dikatakan tepat apabila memenuhi syarat-syarat berikut:
- kelengkapan: dekomposisi relasi R ke dalam fragmen-fragmen R1, …, Rn dikatakan lengkap jika setiap tupel R dapat ditemukan dalam fragmen Ri mana pun.
- rekonstruksi: jika relasi R terdekomposisi ke dalam fragmen-fragmen R1, …, Rn, terdapat operator relasional
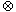 sedemikian sehingga
sedemikian sehingga 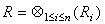 .
. - disjoint: jika sebuah relasi R dipartisi, sebuah tupel dalam R, jika ditemukan dalam fragmen Ri, tidak akan ditemukan dalam fragmen Rj dengan i ? j.
Alokasi
Dalam basis data terdistribusi, alokasi mengacu kepada distribusi data ke tempat yang optimal. Ada tiga aspek dalam memastikan alokasi menjadi optimal, antara lain
- biaya minimal, yang mencakup aspek komunikasi, penyimpanan, dan pemrosesan (pembacaan dan update); biaya mengacu pada waktu dan biaya jaringan
- kinerja, yang mencakup waktu respons dan throughput
- konstrain pemrosesan dan penyimpanan per situs (tempat menyimpan data)
Alokasi – Kebutuhan Informasi
Untuk dapat mengalokasikan basis data terdistribusi secara optimal, dibutuhkan informasi-informasi tentang sistem sebagai berikut:
- informasi basis data
- skema konseptual basis data dan jumlah situs tersedia
- jumlah, ukuran, dan selektivitas fragmen per relasi global
- informasi aplikasi
- jumlah query aplikasi
- rata-rata jumlah akses baca dariquery ke dalam sebuah fragmen
- rata-rata jumlah akses update dari query ke dalam sebuah fragmen
- matriks yang menunjukkan query mana yang meng-update dan/atau membaca fragmen tertentu
- situs asal tiap-tiap query dijalankan
- informasi situs
- unit cost penyimpanan data dalam satu situs
- unit cost pemrosesan data dalam satu situs
- informasi jaringan
- komunikasi antara dua situs, mencakup antara lain bandwidth dan tunda (latency)
Replikasi
Sistem basis data terdistribusi dapat menyimpan duplikat dari data yang sama dalam site yang berbeda agar perolehan informasi yang semakin cepat dan toleransi kesalahan. Proses ini disebut replikasi. Replikasi pada relasi bersifat redundan pada dua atau lebih situs.
Replikasi pada relasi disebut replikasi penuh bila relasi tersebut disimpan pada semua situs. Basis data disebut redundan penuh jika tiap-tiap site mengandung duplikat dari keseluruhan basis data.
Replikasi dilakukan karena memiliki kelebihan sebagai berikut:
- jika situs asli yang menyimpan relasi R mengalami kegagalan, relasi R tetap dapat diakses melalui replikanya
- query pada relasi R dapat berjalan secara paralel di simpul (situs) yang berbeda
- lebih sedikit transfer data, yaitu tidak perlu lagi mengambil data suatu relasi melalui jaringan karena sudah ada replika dalam situs lokal.
Namun, proses replikasi juga memiliki kelemahan, antara lain
- proses update yang lebih rumit karena setiap replika relasi R harus di-update.
- kendali atas konkurensi yang lebih rumit karena update terhadap replika secara konkuren dapat menyebabkan basis data menjadi tidak konsisten sehingga diperlukan mekanisme khusus dalam penanganan konkurensi.
Sementara itu, dalam melakukan replikasi, ada dua strategi, yaitu
- sinkron: sebelum seluruh proses transaksi update dinyatakan selesai, data yang telah dimodifikasi disinkronkan ke setiap duplikatnya; proses ini harus menunggu hingga data di tempat penyimpanan duplikat selesai ditulis sebelum dilakukan perubahan lainnya sehingga menjadi lebih kompleks
- asinkron: copy data diperbaharui secara periodik berdasarkan data utama yang diperbaharui; proses penulisan data selesai tanpa perlu menunggu penulisan data di tempat penyimpanan duplikat selesai; proses ini memang meningkatkan kinerja sistem namun risikonya, inkonsistensi data bisa terjadi.







